

With the release of version 7.1 of the PDF Converter for SharePoint we added a fundamental new technology to our Document Conversion and Manipulation platform, Optical Character Recognition (OCR). That initial release was able to process scanned / bitmap based content and generate fully searchable PDFs.
With the introduction of version 7.2 we are adding support for a new OCR related use case, which is the ability to recognise text on (part of) a page and return the actual text (not a bitmap) to the workflow for further processing. A common use for this functionality is to extract a particular area of text from documents that all use a common template or layout. For example, if a reference number can always be found at the top right corner of scanned documents then that text can be extracted and stored in a SharePoint column from where it can be included in searches or be used in further workflow steps… pretty powerful stuff.
This post describes the Nintex Workflow Activity. The SharePoint Designer equivalent can be found here.
For more details, including an introduction, see these related blog posts.
- OCR Facilities provided by Muhimbi’s server based PDF Conversion products
- Carry out OCR using a web service call (.NET)
- Carry out OCR using a web service call (Java)
- Converting scans and images to searchable PDFs using SharePoint Designer Workflows
- Converting scans and images to searchable PDFs using OCR & Nintex Workflow
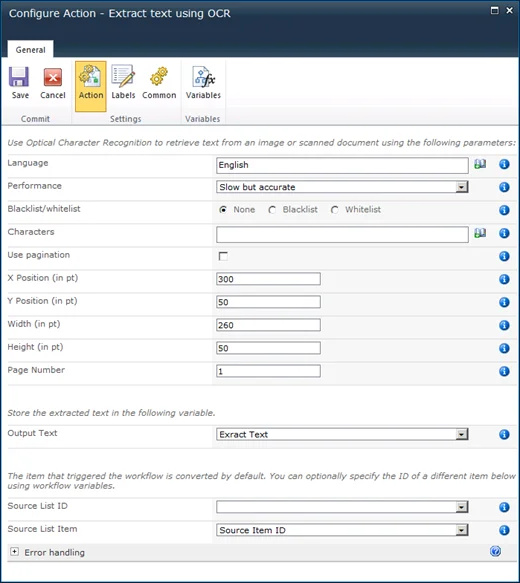
Once the Muhimbi PDF Converter for SharePoint is installed, and the Nintex Workflow Integration has been activated, a number of new activities will be added automatically to the list, including the new Extract text using OCR activity. It is compatible with Nintex Workflow 2007, 2010 & 2013 and this is what it looks like.
Building a full example workflow is out of the scope of this post as it is relatively easy. For details see our generic PDF Conversion for Nintex Workflow example.
The fields supported by this Workflow Activity are as follows:
- Language: The language the source document is written in. It defaults to English, but we currently (version 7.2) support Arabic, Danish, German, English, Dutch, Finnish, French, Hebrew, Hungarian, Italian, Norwegian, Portuguese, Spanish and Swedish.
- Performance: Specify the performance / accuracy of the OCR engine. It is recommended to leave this on the default Slow but accurate setting.
- Whitelist / Blacklist: Control which characters are recognised. For example limit recognition to numbers by whitelisting 1234567890. This prevents, for example, a 0 (zero) to be recognised as the letter o or O.
- Pagination: In some specific cases a single image spans multiple pages. Enable pagination for those cases.
- Region: Specify the x, y, width and height of the region to retrieve text from. The unit of measure (UOM) is 1/72nd of an inch. When extracting text from non-PDF files, e.g. a TIFF or PNG, then please take into account that internally the image is first converted to PDF, which may add margins around the image but guarantees that a single – unified - UOM is used across all file formats. If you are not sure how internal conversion affects the dimensions of your image or scan then use our software to convert the file to PDF and open it in a PDF reader.
- Page Number: By default text is extracted from all pages and concatenated. To extract the text from a specific page specify the page number in this field.
- Output Text: The recognised text will be stored in this variable (type String).
- Source List ID & List Item: The item that triggered the workflow is processed by default. You can optionally specify the ID of a different List and List Item using workflow variables. Please use data type string for the List ID workflow variable. For the Item ID use type Item ID (in SharePoint 2007) or Integer (in SharePoint 2010 / 2013)
- Error Handling: Similar to the way some of Nintex’ own Workflow Activities allow errors to be captured and evaluated by subsequent actions, all of Muhimbi’s Workflow Activities allow the same. By default this facility is disabled meaning that any error terminates the workflow.
For more details about using the PDF Converter for SharePoint in combination with Nintex Workflow see this Knowledge Base article.
Please note that the OCR and PDF/A Archiving Add-On add-on license is needed in order to use OCR in your production environment.
Any questions or comments? Leave a message below or contact us.
Labels: Articles, News, Nintex, OCR, pdf, PDF Converter, PDF Converter Professional, Workflow