

We are happy to announce version 7.2 of the popular Muhimbi PDF Converter Services. This new release further extends the OCR facility and MSG improvements introduced in the previous version and adds support for extracting text from bitmap based content and rendering of MSG based calendar entries.
A quick introduction for those not familiar with the product: The Muhimbi PDF Converter Services is an ‘on premises’ server based SDK that allows software developers to convert typical Office files to PDF format using a robust, scalable but friendly Web Services interface from Java, .NET, Ruby & PHP based solutions. It supports a large number of file types including MS-Office and ODF file formats as well as HTML, MSG (email), EML, AutoCAD and Image based files and is used by some of the largest organisations in the world for mission critical document conversions. In addition to converting documents the product ships with a sophisticated watermarking engine, PDF Splitting and Merging facilities, an OCR facility and the ability to secure PDF files. A separate SharePoint specific version is available as well.
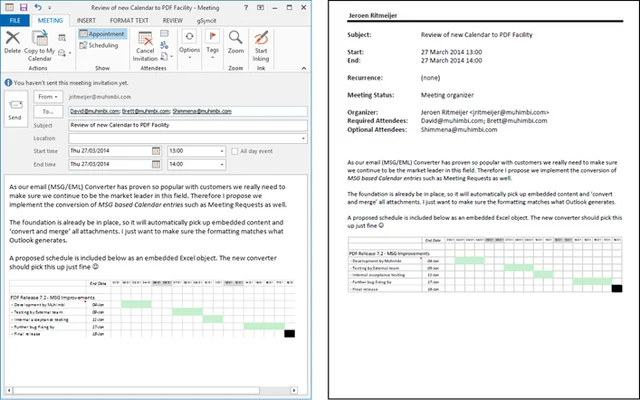 Example of a converted Calendar entry with an (OLE) embedded Excel sheet
Example of a converted Calendar entry with an (OLE) embedded Excel sheet
In addition to the changes listed above, some of the main changes and additions in the new version are as follows:
- 2100 ExcelNewOptionally scale Excel to page width & height
- 2059 HTMLFixSystem.ArgumentException: uri - string can not be empty
- 1996 HTMLImprovementReduce white space causing occasional extra empty PDF pages at end of file.
- 1802 MergingFixBookmark targets bottom of page
- 2093 MergingFix"Unexpected token Unknown before 107448" while merging file
- 2078 MergingFixKernel Error while loading PDF
- 2073 MergingFixSystem.IndexOutOfRangeException while merging
- 2074 MergingFixSystem.NullReferenceException while merging
- 2075 MergingFixSystem.NullReferenceException while merging
- 2076 MergingFixSome HTML Converted files cannot be saved in Acrobat Pro after merging
- 2126 MSGFix"System.InvalidOperationException: Stack empty" during conversion of 3rd party generated MSG files
- 2133 MSGFix"Parameter is not valid" during conversion of 3rd party generated MSG files
- 2136 MSGFixContent missing from converted MSG file
- 2106 MSGFixFixed MSG body for 3rd party generated MSG files
- 2116 MSGFixConversion of MSG files with an attached MSG that is signed
- 2124 MSGFix"System.IndexOutOfRangeException" Converting German email
- 2125 MSGFixConversion of email never finishes
- 2105 MSGFix"Invalid Compressed RTF header" during conversion of 3rd party generated emails
- 2090 MSGFixExtra '}' in body text
- 2058 MSGFixNo bookmark generated for certain attachments
- 2056 MSGFix‘Sent date' not correct on some 3rd party generated emails
- 2057 MSGFixUnicode converter issue (also with EML)
- 2088 MSGImprovementAdd support for attendees to meeting invitations
- 2086 MSGImprovementOptionally throw error if embedded content is encountered that cannot be converted
- 2013 MSGImprovementFrom address shows LDAP path
- 2046 MSGImprovementWeb Service support for MSGConverterFullFidelity.EmailAddressDisplayMode and FromEmailAddressDisplayMode
- 2087 MSGNewConvert the visual representation of embedded objects
- 2068 MSGNewAdd support for the conversion of Calendar Entries
- 2050 MSGNewAdd config value to allow MSG attachments list to be displayed, even when attachments are disabled
- 2113 MSG/HTMLFixRendering error in very long emails / HTML pages
- 2066 MSG/HTMLFixSometimes content is truncated on systems running IE9, IE10 or IE11
- 2005 MSG/HTMLFixFonts look weird in some emails
- 1786 OCRFixHandle leak during OCR
- 2054 OCRFixSome Mixed content (MS-Word files with scanned images) does not always OCR
- 1999 OCRFixArabic training data causes exception
- 1788 OCRImprovementIncrease OCR Performance
- 2089 OCRImprovementUpdate Diagnostics tool to display OCRed text
- 2081 OCRImprovementIn-line images are recognised but text is not placed on it correctly
- 1998 OCRImprovementAdd support for Hebrew
- 2048 OCRNewSupport for extracting text from bitmap based content using OCR
- 2072 OtherNewAllow timeouts to be specified on web service call
- 2102 WatermarkingFixChinese & Japanese fonts are not displayed in watermarks
- 2103 WatermarkingFixWatermarking some documents causes problem in Adobe Reader 9
For more information check out the following resources:
- Product Page.
- Brochure.
- Release Notes.
- Administration Guide.
- User & Developer Guide.
- FAQ & Knowledge Base.
- Discussion Forum.
- All PDF Converter Services related Blog Posts.
As always, feel free to contact us using Twitter, our Blog, regular email or subscribe to our newsletter.
Download your free trial here (39MB). .
Labels: News, OCR, PDF Converter Professional, PDF Converter Services