
As part of our on-going series about new features in the PDF Converter for SharePoint On-Premises 4.0 and PDF Converter Services, we would like to showcase our exciting new HTML to PDF conversion functionality.
Please note that this article mentions SharePoint as well as .NET a number of times. Rest assured that, as the PDF Converter Services is Web Services based, it works just as well from Java, C#, Ruby and other web services capable environments.
We anticipate that most of our customers will use this functionality to convert SharePoint pages, including lists, to PDF format. However, rather than displaying a boring old SharePoint site, let’s show how well this works with a real website, in this case one of our landing pages.
UPDATE: A workflow activity is now available as well for converting HTML to PDF as is an update for the SharePoint User interface to convert SharePoint pages to PDF format.
The following image shows the original HTML page on the left hand side and the converted PDF file on the right. As you can see this works very well.
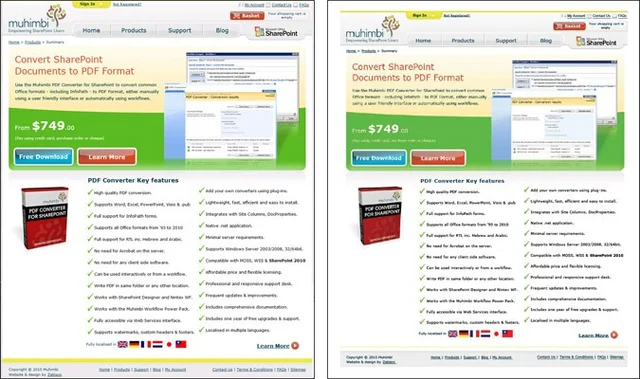 Example of the original web page (left) and the converted PDF file (right)
Example of the original web page (left) and the converted PDF file (right)
A summary of the new HTML features are as follows. Although this new functionality is available in both the PDF Converter Services as well as the PDF Converter for SharePoint On-Premises, some of the more SharePoint centric features in the list are obviously exclusive to the SharePoint version.
Built on top of Muhimbi’s rock solid service platform. No need to worry about runaway or orphaned processes. Everything is nicely controlled and scales over multiple CPUs and conversion servers.
Integrates with the full feature set of Muhimbi’s PDF Conversion platform including full control over watermarks as well as PDF Security settings.
High fidelity conversion (See image above) including multi page documents and JavaScript output. The generated PDF file contains real (searchable) text and is not just a low resolution screenshot of the converted web page.
Supports conversion by URL as well as manually specified HTML fragments. Ideal for creating PDF based reports using generated HTML tables.
Convert HTML documents stored inside SharePoint document libraries.
Convert SharePoint pages to PDF format from the user’s Personal Actions menu.
Convert web pages to PDF format from SharePoint workflows. Works great in combination with publishing sites.
HTML to PDF Conversion is accessible via the web services based interface as well. Listed below is a simple C# example of how to carry out a conversion from your own code. The code is not complete as it calls into some shared functions from our main C# example to keep things short.
Our existing Java based examples can easily be extended to carry out the same type of conversions. Contact us if you need a hand, we love to help and are very responsive.
All in all some pretty exciting functionality. Don’t hesitate to leave a comment below if you have any questions or contact us to discuss any of our products.
Labels: Articles, Java, News, pdf, PDF Converter, PDF Converter Services